¿Qué
es el chipset?
Es el
componente más importante de la tarjeta madre, es un grupo de chips que
trabajan en conjunto para realizar una tarea determinada y su misión es
comunicar a todos los elementos que componen el sistema.
El chipset
especificara las prestaciones de la tarjeta madre, es decir, el chipset
condiciona que procesador soportara la tarjeta madre, a que frecuencia operaran
los buses, que tipo de memoria RAM será compatible, y que interfaces de video,
disco y los demás puertos serán soportados.
Es ahí
donde radica la importancia de conocer sobre el chipset al momento de elegir
una computadora.
Funciones y aplicaciones:
El chipset
es fundamental para que cualquier computadora funcione ya que es el encargado
de enviar las órdenes de la tarjeta madre a procesador para que ambos puedan
trabajar con armonía, es decir, permite que la tarjeta madre sea el eje central
de nuestra PC comunicando a sus componentes a través de buses
Además se
encarga de administrar la información que ingresa y egresa a través de bus
principal del procesador e inclusive su función se extiende al uso de la
memoria RAM, ROM y las placas de video.
También
puede controla la velocidad y la función de la memoria ram, administrar
diversos tipos de buses, los discos rigidos y su ancho de banda, asi como
gestionar la calidad del acelerador grafico.
El chipset
y la tarjeta madre forma un conjunto indisoluble muy importante, se debe tener
en cuenta que un buen chipset por si mismo no implica que la tarjeta madre sea
en conjunto de calidad.
Como
está conformado el chipset (características):
El chipset
está formado por dos componentes principales el northbridge (puente norte) y e
southbridge (puente sur), cuyos nombre provienen de su ubicación dentro del PCB
(circuito impreso) de la tarjera madre, si miramos verticalmente el northbridge
quedara junto al procesador mientras que el southbridge quedara abajo junto a
las placas de expansión

En
la actualidad el northbridge se encuentra integrado dentro del microprocesador.
Importancia:
El
northbridge es la parte principal del chipset, se encarga de controlar el
tráfico entre el procesador, la memoria RAM, la interfaz de video, las ranuras
de expansión y el southbridge a través de una interconexión de buses.
El objetivo
del southbridge es controlar un gran número de dispositivos como la PCI
(componentes periféricos de interconexión), los puertos USB, el firewire, así
como los controladores de las unidades serial ATA y parallel ATA, entre otras
funciones importantes.
El chipset
es sin duda alguna uno de los componentes más importantes de la
computadora y a su vez es el elemento más olvidado, sin embargo es el encargado
de comunicar todos los elementos haciendo posible el funcionamiento del
sistema, es por eso que se puede considerar la columna vertebral de la
computadora.
Aqui dejamos un link para obtener mas informacion sobre los Chipsets
CPU
CPP o
procesador, interpreta y lleva a cabo las instrucciones de los programas,
efectúa manipulaciones aritméticas y lógicas con los datos y se comunica con
las demás partes del sistema. Una CPU es una colección compleja de circuitos
electrónicos. Cuando se incorporan todos estos circuitos en un chip de silicio,
a este chip se le denomina microprocesador. La CPU y otros chips y componentes
electrónicos se ubican en un tablero de circuitos o tarjeta madre2.
El chip más
importante de cualquier placa madre es el procesador. Sin el la computadora no
podría funcionar. A menudo este componente se determina CPU, que describe a la
perfección su papel dentro del sistema. El procesador es realmente el elemento
central del proceso de procesamiento de datos.
Los
procesadores se describen en términos de su tamaño de palabra, su velocidad y
la capacidad de su RAM asociada.
Tamaño de
la palabra: Es el número de bits que se maneja como una unidad en un sistema de
computación en particular.
Velocidad
del procesador: Se mide en diferentes unidades según el tipo de computador:
MHz
(Megahertz): para microcomputadoras. Un oscilador de cristal controla la
ejecución de instrucciones dentro del procesador. La velocidad del procesador
de una micro se mide por su frecuencia de oscilación o por el número de ciclos
de reloj por segundo. El tiempo transcurrido para un ciclo de reloj es
1/frecuencia1.
MIPS
(Millones de instrucciones por segundo): Para estaciones de trabajo, minis y
macrocomputadoras. Por ejemplo una computadora de 100 MIPS puede ejecutar 100
millones de instrucciones por segundo.
FLOPS
(floating point operations per second, operaciones de punto flotante por
segundo): Para las supercomputadoras. Las operaciones de punto flotante
incluyen cifras muy pequeñas o muy altas. Hay supercomputadoras para las cuales
se puede hablar de GFLOPS (Gigaflops, es decir 1.000 millones de FLOPS)2.
Capacidad
de la RAM: Se mide en términos del número de bytes que puede almacenar.
Habitualmente se mide en KB y MB, aunque ya hay computadoras en las que se debe
hablar de GB.
Controlador de Bus Ensamble
Componentes
El
controlador del bus se encarga de la frecuencia de funcionamiento y las señales
de sincronismo, temporización y control.
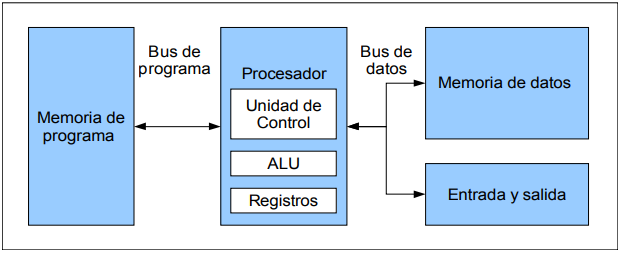
El Bus es
la vía a través de la que se van a transmitir y recibir todas las
comunicaciones, tanto internas como externas, del sistema informático. El bus
es solamente un Dispositivo de Transferencia de Información entre los
componentes conectados a él, no almacena información alguna en ningún momento.
Los datos, en forma de señal eléctrica, sólo permanecen en el bus el tiempo que
necesitan en recorrer la distancia entre los dos componentes implicados en la
transferencia.
Puertos De E/S
PUERTO
PARALELO
El puerto
paralelo (protocolo Centronics) se utiliza generalmente para manejar
impresoras. Sin embargo, dado que este puerto tiene un conjunto de entradas y
salidas digitales, se puede emplear para hacer prácticas experimentales de
lectura de datos y control de dispositivos Un puerto paralelo es una interfaz
entre un ordenador y un periférico cuya principal característica es que los
bits de datos viajan juntos enviando un byte (8 bits) completo o más a la vez.
Es decir, se implementa un cable o una vía física para cada bit de datos formando
un bus. El puerto paralelo más conocido es el puerto de impresora.
Se conoce
cuatro tipos de puerto paralelo:
· Puerto
paralelo estándar (Standart Parallel Port SPP)
· Puerto
Paralelo PS/2 (bidireccional)
· Enhanced
Parallel Port (EPP)
· Extended Capability Port (ECP)
Controlador Interrupciones
Este
circuito integrado controla las interrupciones del sistema. Como el
microprocesador sólo posee dos entradas de interrupción, y puede controlar
muchas más, es necesario algún integrado que no permita ello. El 8259 cumple
este propósito.
El
funcionamiento del 8259 es muy sencillo: Supongamos que no queda ninguna
interrupción pendiente y el CPU está trabajando en el “Programa principal”. Al
activarse una línea de interrupción, el 8259 verifica que no haya otra
interrupción pendiente, y si no la hay, envía una señal a través del pin INTR
hacia el pin INTR del CPU, adicionalmente, envía a través del bus de datos, el
número de interrupción que se ha activado, de tal manera que el CPU ya sabe qué
servicio de interrupción va a usar. Una vez que recibió el CPU este valor,
activa su pin INTA, indicando que ya recibió y está ejecutando el servicio. Una
vez que el CPU termina, el pin INTA se desactiva, indicando al 8259 que está
listo para procesar otras interrupciones.
Las rutinas
de los servicios de interrupción están vectorizadas en las primeras posiciones
de memoria, y están distribuidas de la manera siguiente: El los dos primeros
bytes corresponden al valor que irá al registro IP, que indica el
desplazamiento; y los dos siguientes, corresponden al registro CS, que indica
el segmento donde está el servicio de interrupción. Estos dos pares de bytes se
inician en la posición de memoria 0000h y corresponden a la interrupción 0; los
siguientes cuatro corresponden a la interrupción 1, y así sucesivamente hasta
las 256 interrupciones (total 1024 bytes). Esto significa que el usuario puede
crear su propio servicio de interrupción y accederlo a través de la
manipulación de estos bytes.El 8259, posee varios modos de configuración,
dependiendo de la manera cómo se desea que se traten a las interrupciones
Hay que
tener en cuenta que la interrupción no enmascarable NMI, va directamente a CPU
y es la encargada de indicar errores de paridad en la memoria, fallos de
circuiteria y el procesador matemático. En el PC/XT original es posible un
total de 256 interrupciones, de las cuales 8 son por hardware y las demás por
software.
Controlador Dma
El acceso
directo a memoria (DMA, del inglés direct memory access) permite a cierto tipo
de componentes de una computadora acceder a la memoria del sistema para leer o
escribir independientemente de la unidad central de procesamiento (CPU)
principal. 1Muchos sistemas hardware utilizan DMA, incluyendo controladores de
unidades de disco, tarjetas gráficas y tarjetas de sonido. DMA es una
característica esencial en todos los ordenadores modernos, ya que permite a
dispositivos de diferentes velocidades comunicarse sin someter a la CPU a una
carga masiva de interrupciones.
Una
transferencia DMA consiste principalmente en copiar un bloque de memoria de un
dispositivo a otro. En lugar de que la CPU inicie la transferencia, esta se
lleva a cabo por el controlador DMA. Un ejemplo típico es mover un bloque de
memoria desde una memoria externa a una interna más rápida. Tal operación no ocupa
al procesador y, por ende, éste puede efectuar otras tareas. Las transferencias
DMA son esenciales para aumentar el rendimiento de aplicaciones que requieran
muchos recursos.
El Circuito de temporizador y
control
Es una red
secuencial que acepta un código que define la operación que se va a ejecutar y
luego prosigue a través de una secuencia de estados, generando una
correspondiente secuencia de señales de control. Estas señales de control
incluyen el control de lectura ‑ escritura y señales de dirección de memoria válida en el bus
de control del sistema. Otras señales generadas por el controlador se conectan
a la unidad aritmética ‑ lógica y a los registros internos del procesador para regular el flujo de
información en el
procesador y a, y desde, los buses de dirección y de datos del sistema.
Controladores De Video
Un
controlador de vídeo o VDC es un circuito integrado que es el principal
componente de un generador de señal de vídeo, un dispositivo encargado de la
producción de una señal de vídeo en informática o un sistema de juego. Algunos
de Desarrollo de Aldea también generar una buena señal, pero en ese caso no es
su función principal3.
La mayoría
de los CDA se utilizan a menudo en la antigua casa-ordenadores de los años 80,
sino también en algunos de los primeros sistemas de video juego.
El VDC
siempre es el principal componente de la señal de vídeo generador de la lógica,
pero a veces también hay otros chips utilizados, tales como RAM para celebrar
el píxel de datos, para celebrar ROM carácter fuentes, o quizás algunos
discretos lógica, como los registros de cambio eran necesarias para construir
un sistema completo. En cualquier caso, es el VDC de la responsabilidad de
generar el calendario de las necesarias señales de vídeo, tales como la
horizontal y vertical de sincronización de señales, y el intervalo de corte de
señal.
REFERENCIAS
[1] Sánchez Iglesias, Á. (2017). ¿Qué es el chipset de un PC?. aboutespanol. de https://www.aboutespanol.com/que-es-el-chipset-de-un-pc-841341
[2] Gallego, José Carlos; Folgado, Laura (27 de julio de 2011). Montaje y mantenimiento de equipos. Editex. Consultado el 18 de octubre de 2017.
[3] Tejada, Ester Chicano (6 de noviembre de 2015). Gestionar el crecimiento y las condiciones ambientales. IFCT0510. IC Editorial. Consultado el 18 de octubre de 2017.
[5] Montero, Isidoro Berral (2014). Montaje y mantenimiento de sistemas y componentes informáticos. Ediciones Paraninfo, S.A. Consultado el 18 de octubre de 2017.